데이터 구조 파악 (EDA)
EDA(탐색적 데이터 분석, Exploratory Data Analysis)는 데이터 분석을 수행하기 전에 데이터의 구조를 파악하고 특성을 이해하는 과정. 기술통계, 데이터 시각화, 변수 간 관계 분석 등의 방법을 사용하며 데이터의 패턴을 발견하고 이상치(outlier) 및 결측치(missing value)를 확인해 적절한 전처리 방법 결정 가능.
1. 데이터의 기본 정보 파악: 데이터 크기, 컬럼 수, 데이터 타입 등 확인.

2. 결측치, 이상치 탐색: 누락된 값과 비정상적인 값을 찾아 적절한 처리 방안 결정.


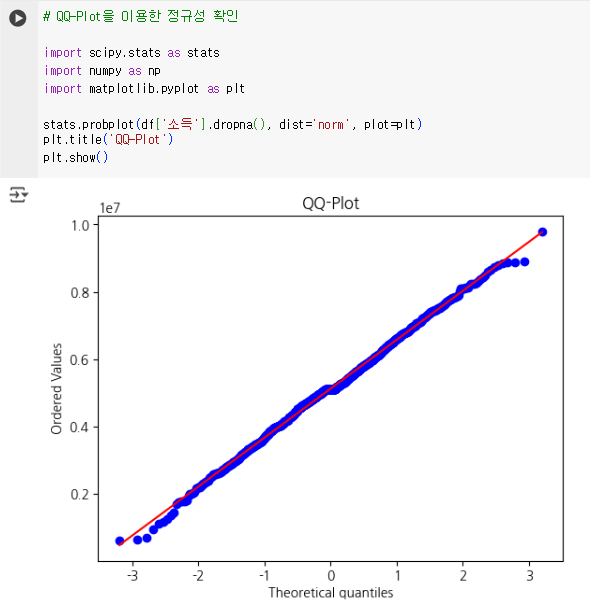
3. 데이터 분포 확인: 데이터가 정규분포를 따라는지 여부 등을 시각적으로 확인.

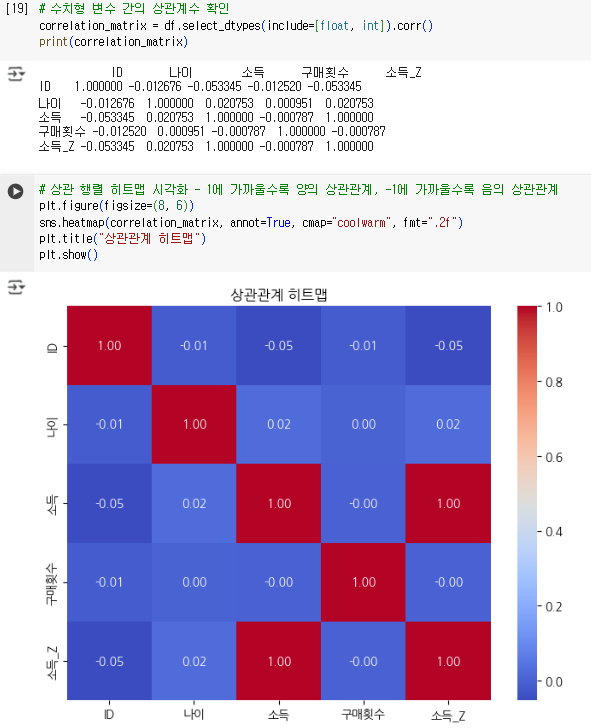
5. 변수 간 관계 분석 및 시각화: 상관관계를 분석해 데이터의 패턴 이해.
6. 데이터 정리 및 이상치 제거: EDA를 통해 발견한 문제를 해결하기 위해 데이터 정리

| 데이터 로드 및 정보 확인 | 데이터셋 불러오기 및 기본 정보 확인 | pandas, .info(), .describe() |
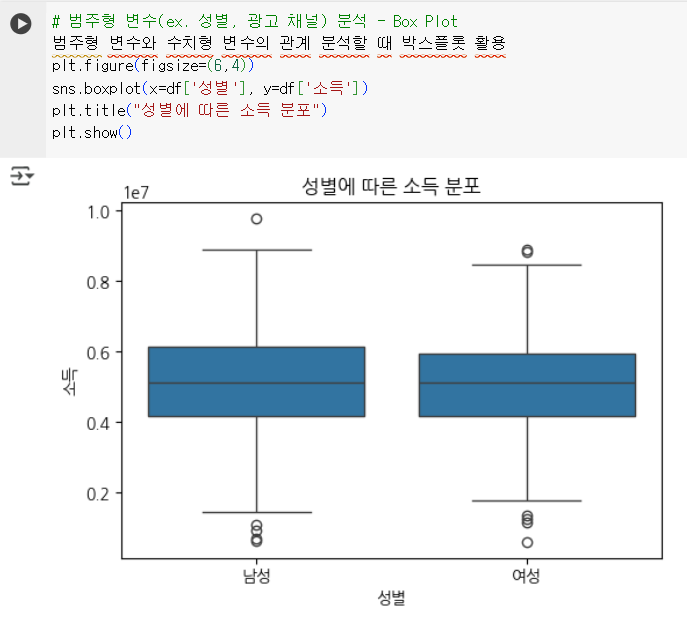
| 결측치 및 이상치 탐색 | 결측치 및 이상치 탐색 및 처리 | .isnull(), fillna(), 박스플롯 |
| 기술통계를 활용한 데이터 요약 | 데이터 분포 및 특성 분석 | 히스토그램, 평균/표준편차 |
| 변수 간 관계 분석 | 변수 간 상관관계 분석 | 상관 행렬, 산점도, 바 차트 |
| 결론 도출 및 마케팅 전략 수립 | 분석 결과를 바탕으로 마케팅 최적화 | 맞춤형 프로모션, 광고 최적화 |
(실습) EDA를 활용한 그로스 마케팅 분석 시나리오
그로스 마케팅에서는 다양한 KPI(Key Performance Indicator)를 분석해야 한다.
| 신규 고객 vs 기존 고객 비율 | 신규 유입 대 기존 고객의 비율 분석 | 파이 차트 (Pie Chart) |
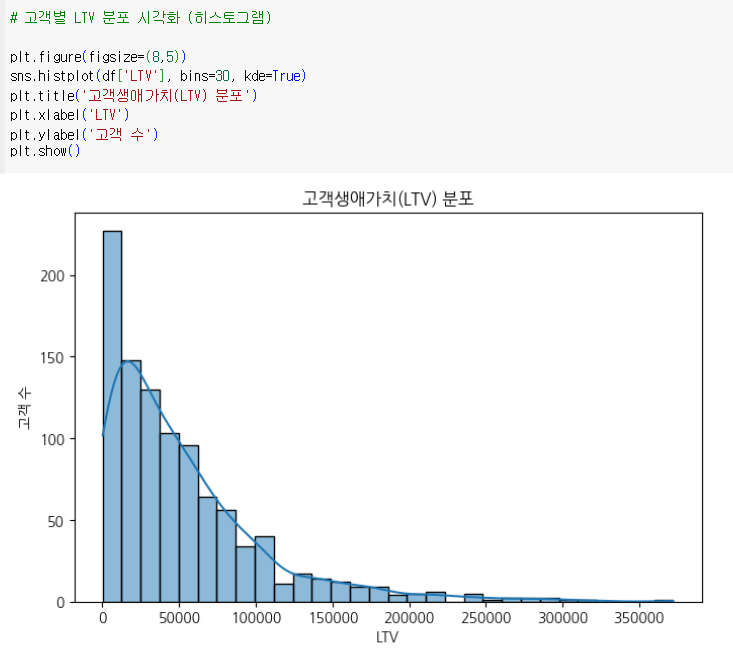
| 고객별 생애가치(LTV) 분석 | 고객의 생애가치(lifetime value) 분석 | 히스토그램 (Histogram) |
| 이탈률(churn rate) 분석 | 이탈한 고객과 유지된 고객 비교 | 박스플롯 (Box Plot) |
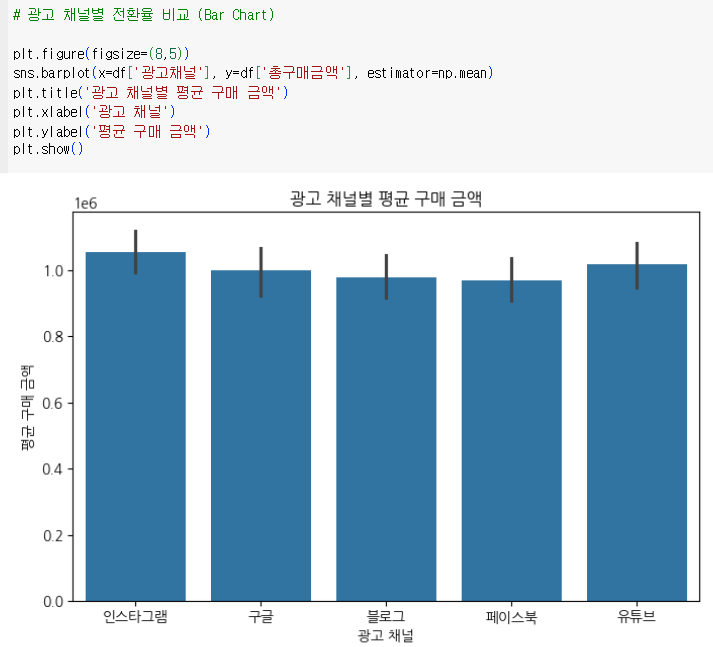
| 광고 채널별 전환율 | 광고 채널별 고객 전환율 비교 | 막대 그래프 (Bar Chart) |
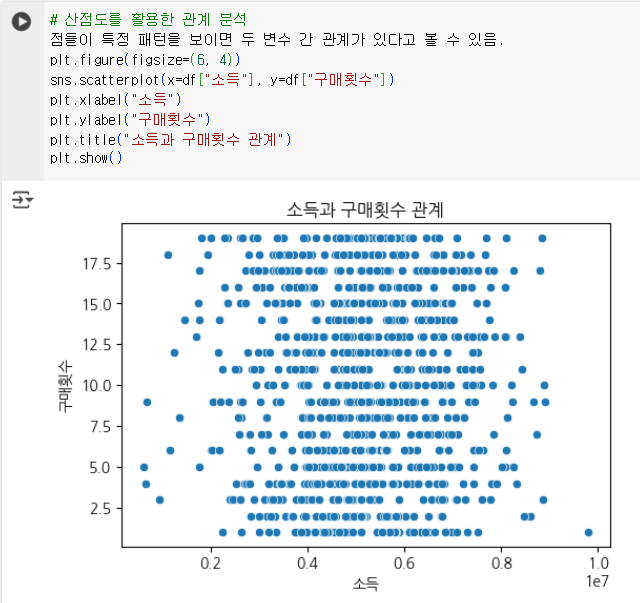
| 소득 vs 구매액 상관관계 | 월 소득이 높은 고객이 구매를 많이 하는지 분석 | 산점도 (Scatter Plot) |
한 온라인 쇼핑몰에서 고객 데이터를 활용해 마케팅 전략을 개선하고자 한다 - 신규 고객의 행동 패턴을 파악하고 충성 고객을 분석해 재구매율을 높이는 전략을 세워보자.
EDA를 위한 시각화 코드:

데이터 분석 및 그래프 시각화:
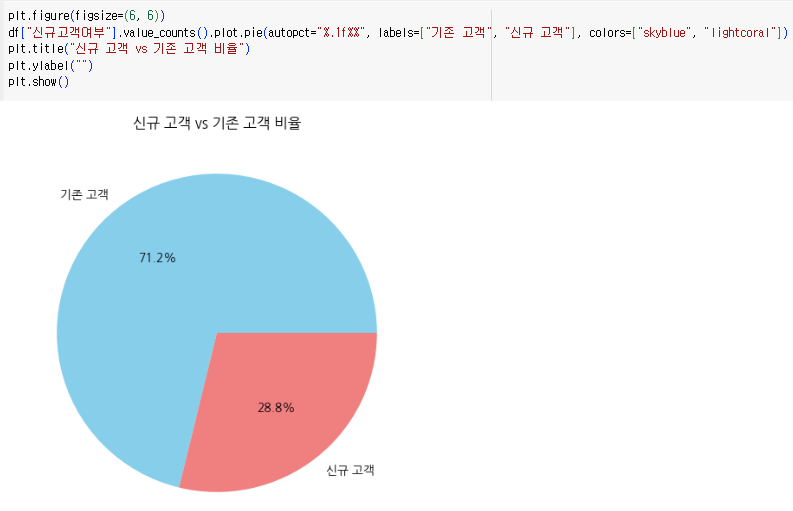


- 신규 고객 유입을 증대시키기 위한 전략 필요 (ex. 검색광고 확대, 프로모션 강화 등)
- 대부분 고객이 LTV가 낮은 구간에 분포되어 있어, LTV가 높은 소수의 고객을 VIP로 분류해 맞춤형 혜택 제공 등 리텐션 위한 마케팅 전략 필요
- 유지 고객이 이탈 고객에 비해 높은 이상치를 보임 → 유지 고객의 일부가 높은 구매액을 지속적으로 기록하고 있다는 뜻.
- 이탈 고객의 최대 구매액이 유지 고객보다 높아, 고액으로 일회성 소비 후 이탈한 고객이 존재한다는 점을 추정 가능.
- 평균 구매액은 이탈 고객이 유지 고객에 비해 낮으므로, 맞춤형 할인이나 재구매 유도 캠페인 진행해 이탈 방지 시도.
- 전환 효율이 높은 순(IG>YT>GG>BL>FB)으로 광고 채널별 예산 할당해 ROAS 최적화.
- 고객별 월소득과 총 구매액의 상관계수는 -0.02로, 유의미한 관계가 거의 없다고 볼 수 있음.
한 구독기반 서비스 운영팀이 고객 데이터를 기반으로 구독 유지율을 높이기 위한 KPI를 설정하고 분석하는 데이터 보고서를 작성하려 한다. 총 2000명의 구독 고객 데이터셋을 탐색적으로 분석해 고객 이탈 패턴을 분석하고 시각화해서 고객 리텐션 전략을 제안하세요
1. 데이터 전처리 및 기본 탐색: 데이터셋을 로드하고, 기본적인 전처리를 수행해 데이터 정리
- 데이터셋 파일(CSV)을 pandas로 로드 (pd.read_csv("파일명.csv"))
- df.describe()와 df.info()로 데이터셋 구조 확인 / 결측치 확인


2. 고객 이탈 원인 분석: 구독 유지 고객과 이탈 고객을 비교 분석해 원인 추정
- sns.boxplot()을 통해 유지 고객-이탈 고객의 결제 금액 분포 시각화
- 구독상태 별로 평균 결제 금액 차이가 유의미한지 T-test 수행

※ 박스 플롯(Box Plot) 쉽게 이해하기 (source: GPT 센세)
┌──────────┐ ← 상자(Box): 중앙 50% 데이터 (제1사분위수–제3사분위수)
│ │
│ ── ── ── ← 중앙선(Median): 데이터의 중간값 (제2사분위수)
│ │
└──────────┘
│ │ ← 수염(Whisker): 보통 IQR(사분위 범위)의 1.5배 안쪽 극단값까지
○ ○ ← 동그라미(Outlier): 수염 바깥의 극단값
- 박스 아래끝(하단 경계): 제1사분위수(Q1, 하위 25%)
- 박스 위끝(상단 경계): 제3사분위수(Q3, 상위 25%)
- 박스 안의 가로선: 중앙값(Median, 50%)
- 수염(Whiskers): 일반적으로 Q1−1.5×IQR ~ Q3+1.5×IQR 범위
- 동그라미(Outlier): 수염 바깥에 있는 값들
| 구분 | 대략적인 중앙값 | IQR (박스 높이) | 수염 범위 | 특장 |
| 이탈 고객 | 약 15,000 | 약 12,000~18,000 | 약 2,000~27,000 | 상·하위 극단치(>28,000) 몇 건 존재 |
| 유지 고객 | 약 15,000 | 약 11,500~18,500 | 약 2,500~28,000 | 유사하게 위쪽에 몇 건의 아웃라이어 |
- 중앙값(검은 실선)이 두 그룹 모두 약 15,000원 부근에 위치해 있어, 결제액의 ‘중간값’은 거의 비슷.
- IQR(박스 높이)도 두 그룹이 크게 다르지 않아서, 고객의 상·중·하위 50%가 분포하는 폭이 비슷.
- 수염 범위 역시 비슷하며, 극단적으로 결제액이 높은 이상치가 두 그룹 모두 존재.
T-검정: 두 집단의 평균(혹은 분산이 같다는 가정 하에)을 비교해 "두 집단의 모평균이 동일하다"는 귀무가설(null hypothesis)을 검증하는 통계 기법.
- 검정 통계량(T-statistic): 두 그룹 평균의 차이가 표준오차 대비 얼마나 큰지를 나타내는 값.
- 여기서는 약 −0.92로, ‘평균 차이가 표준오차의 0.92배 크기’ 정도라는 뜻.
- P-값(P-value): “귀무가설이 참일 때(실제로 차이가 없을 때) 관측된 것과 같거나 더 극단적인 결과가 나올 확률”
- 여기서는 0.356(≈35.6%)로, 흔히 사용하는 유의수준 0.05(5%)보다 훨씬 크다.
- P-값이 0.05보다 크면 “평균이 같다(차이가 없다)”는 귀무가설을 기각할 근거가 부족하다고 판단.
결론: 박스 플롯 상으로도, T-test 결과로도 유지 고객과 이탈 고객의 결제액 분포는 통계적으로 유의미한 차이가 볼 수 없다고 분석할 수 있다. 결제 금액 자체만으로는 고객이 이탈할지 유지할지 예측하기 어려워 보이며, 다른 요인들이 복합적으로 작용한 결과의 현상으로 봐야 할 것.
3. 서비스 이용 패턴과 이탈률 분석: 월평균 이용 시간과 고객 유형별에 따라 이탈률 분석


월평균 이용시간이 높은 고객들이 낮은 고객들에 비해 상대적으로 이탈률이 낮으나 차이가 크지 않아 유의미한 상관관계가 있다고 보기는 어려움. 일반 고객이 프리미엄, VIP 고객에 비해 이탈률이 높아 일반 고객 대상으로 프리미엄 체험권 한달 무료 제공, 단계별 리워드 프로그램 강화 등을 통해 유료 구독 전환 유도 가능.
4. 할인 및 프로모션 효과 분석: 할인사용여부가 고객 유지율에 미치는 영향 분석
- Bar Chart로 시각화

※ 에러바(검정색 세로선): 평균 유지율 값의 표준오차(Standard Error) 또는 신뢰구간(Confidence Interval)을 나타냄
- 에러바가 서로 겹친다는 것은 두 그룹 간 평균값 차이가 통계적으로 크지 않을 가능성이 높다는 의미
할인 사용 고객과 미사용 고객의 구독 유지율이 크게 차이나지 않고, 두 막대의 에러바가 서로 넉넉히 겹치고 있어 할인 사용 여부가 구독 유지율에 있어서 유의미한 변수가 된다고 보기엔 어려움. 할인을 스콥(%)이나 프로모션 종류(첫 달 무료, 이중 할인 등) 별로 세분화해 분석하거나, 고객 세그먼트(신규 vs 재구독 vs 장기구독 vs VIP) 별 효과를 비교하거나, A/B 테스트를 통해 최적의 할인 타이밍을 찾아보는 등의 추가 분석 제안 가능.
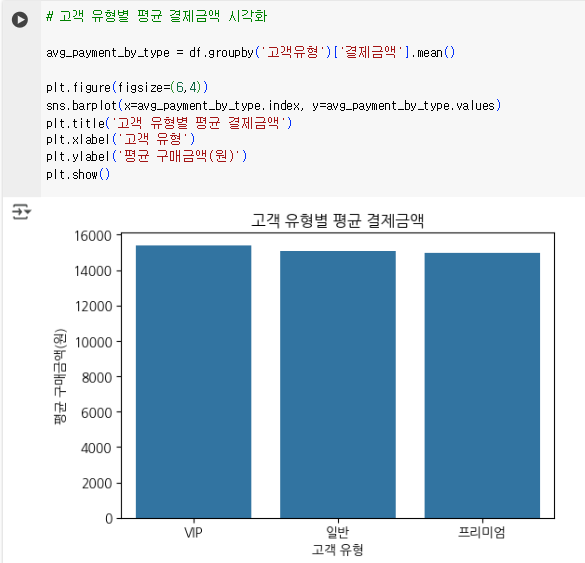
5. 고객 유형별 구독 유지 패턴 분석: 고객 유형별로 구독 유지율 분석해 차별화된 리텐션 전략 수립
- 고객유형 별 평균 구독기간 비교
- sns.barplot() 사용해 고객 유형별 평균 결제금액 시각화

'Bootcamp' 카테고리의 다른 글
| 마케팅 지표 간 상관관계(correlation) 분석 (1) | 2025.06.04 |
|---|---|
| 마케팅 데이터 통계 분석 (추론통계, 회귀분석) (1) | 2025.05.30 |
| Matplotlib으로 그래프 만들기, 데이터 변환, 표준화, 정규화 (0) | 2025.05.27 |
| 서베이 기반 데이터 수집 및 전처리, Matplotlib으로 데이터 시각화하기 (0) | 2025.05.26 |
| 웹 크롤링(Crawling), API를 통한 마케팅 데이터 수집 및 분석 (2) | 2025.05.26 |